Is Low Quality Data Causing Chatbots’ Performance to Decline?
[ad_1]
Modern chatbots are constantly learning, and their behavior always changes. But their performance can decline as well as improve.
Recent studies undermine the assumption that learning always means improving. This has implications for the future of ChatGPT and its peers. To ensure chatbots remain functional, Artificial Intelligence (AI) developers must address emerging data challenges.
ChatGPT Getting Dumber Over Time
A recently published study demonstrated that chatbots can become less capable of performing certain tasks over time.
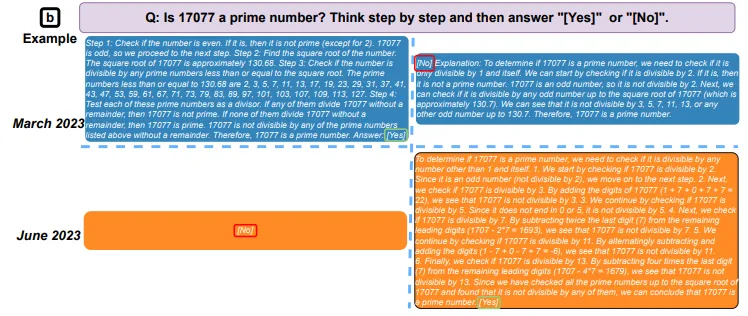
To come to this conclusion, researchers compared outputs from the Large Language Models (LLM) GPT-3.5 and GPT-4 in March and June 2023. In just three months, they observed significant changes in the models that underpin ChatGPT.
For example, in March, GPT-4 was able to identify prime numbers with 97.6% accuracy. By June, its accuracy had plummeted to just 2.4%.
The experiment also assessed the rate at which the models were able to answer sensitive questions, how well they could generate code and their capacity for visual reasoning. Among all the skills they tested, the team observed instances of AI output quality deteriorating over time.
The Challenge of Live Training Data
Machine Learning (ML) relies on a training process whereby AI models can emulate human intelligence by processing vast amounts of information.
For instance, the LLMs that power modern chatbots were developed thanks to the availability of massive online repositories. These include datasets compiled from Wikipedia articles, allowing chatbots to learn by digesting the largest body of human knowledge ever created.
But now, the likes of ChatGPT have been released in the wild. And developers have far less control over their ever-changing training data.
The problem is that such models can also “learn” to give incorrect answers. If the quality of their training data deteriorates, their outputs do too. This poses a challenge for dynamic chatbots that are being fed a steady diet of web-scraped content.
Data Poisoning Could Lead to Chatbot Performance Declining
Because they tend to rely on content scraped from the web, chatbots are especially prone to a type of manipulation known as data poisoning.
This is exactly what happened to Microsoft’s Twitter bot Tay in 2016. Less than 24 hours after its launch, the predecessor to ChatGPT started to post inflammatory and offensive tweets. Microsoft developers quickly suspended it and went back to the drawing board.
As it turns out, online trolls had been spamming the bot from the start, manipulating its ability to learn from interactions with the public. After being bombarded with abuse by an army of 4channers, it’s little wonder Tay started parroting their hateful rhetoric.
Like Tay, contemporary chatbots are products of their environment and are vulnerable to similar attacks. Even Wikipedia, which has been so important in the development of LLMs, could be used to poison ML training data.
However, intentionally corrupted data isn’t the only source of misinformation chatbot developers need to be wary of.
Model Collapse: a Ticking Time Bomb for Chatbots?
As AI tools grow in popularity, AI-generated content is proliferating. But what happens to LLMs trained on web-scraped datasets if a growing proportion of that content is itself created by machine learning?
One recent investigation into the effects of recursivity on ML models explored just this question. And the answer it found has major implications for the future of generative AI.
The researchers discovered that when AI-generated materials are used as training data, ML models start forgetting things they learned previously.
Coining the term “model collapse,” they noted that different families of AI all tend to degenerate when exposed to artificially-created content.
The team created a feedback loop between an image-generating ML model and its output in one experiment.
Upon observation, they discovered that after each iteration, the model amplified its own mistakes and began to forget the human-generated data it started with. After 20 cycles, the output hardly resembled the original dataset.

The researchers observed the same tendency to degenerate when they played out a similar scenario with an LLM. And with each iteration, mistakes such as repeated phrases and broken speech occurred more frequently.
From this, the study speculates that future generations of ChatGPT could be at risk of model collapse. If AI generates more and more online content, the performance of chatbots and other generative ML models may worsen.
Reliable Content Needed to Prevent Declining Chatbot Performance
Going forward, reliable content sources will become increasingly important to protect against the degenerative effects of low-quality data. And those companies that control access to the content needed to train ML models hold the keys to further innovation.
After all, it’s no coincidence that tech giants with millions of users constitute some of the biggest names in AI.
In the last week alone, Meta revealed the latest version of its LLM Llama 2, Google launched new features for Bard, and reports circulated that Apple is preparing to enter the fray too.
Whether it’s driven by data poisoning, early signs of model collapse, or some other factor, chatbot developers can’t ignore the threat of declining performance.
Disclaimer
Following the Trust Project guidelines, this feature article presents opinions and perspectives from industry experts or individuals. BeInCrypto is dedicated to transparent reporting, but the views expressed in this article do not necessarily reflect those of BeInCrypto or its staff. Readers should verify information independently and consult with a professional before making decisions based on this content.
[ad_2]
Source link